
Wordalisation & Context Engineering: What Finally Made My RAG System Sound Like Football

My RAG system was technically correct but the resulting insights were useless for an analyst or a scout.
The numbers and metrics were being computed, the LLM was receiving them, acknowledging them, and then repeating them back to me as if reading from a spreadsheet.
“Home xG was 1.2 and they scored 3 goals. Away PPDA was 4.8, indicating a high press...”
There was no enriched analysis it was just data recitation that didn’t sound like football language.
I was using claude-haiku-4.5 which is capable of writing football language. If you ask it to analyze a match in prose it’ll produce something close to what a scout would write. The model actually knew what a high press looked like, what a low block meant, defensive compactness, progressive passing patterns, etc, but by asking it to recite metrics I just wasn’t letting it “speak” football.
The problem was my prompt not the model
I was passing raw floats directly to the LLM (PPDA of 4.8, expected goals of 1.2, progressive pass counts, compactness scores) and then instructing it to “state only what the metrics directly prove” with “technical terminology and neutral tone.”
David Sumpter, the brain behind Soccermatics and Twelve Football, calls the solution → Wordalisation. The idea is straightforward: before you call the LLM, classify your raw metrics into qualitative English labels. The model never sees the numbers. It only sees what those numbers mean in the language of the domain.
Here’s what the change looked like in practice.
Before, the user prompt contained something like this:
home_ppda: 4.8
home_high_press_count: 12
home_compactness: 33.4
home_field_tilt: 67.9After applying Wordalisation, the LLM received this instead:
home_press_style: pressed_aggressively_allowing_few_passes
home_defensive_shape: compact_block
home_territorial_dominance: dominated_final_third
home_shot_quality: created_high_quality_chancesJust English labels describing what the team actually did, derived from the real Eredivisie 2025-2026 distributions rather than arbitrary thresholds.
The smoke test output shifted the result for good:
Before:
“Home xG was 1.2 and they scored 3 goals. Away PPDA was 4.8...”
After:
“Heracles set up to frustrate, sitting deep and inviting PEC Zwolle to come at them — a coherent enough plan in isolation, but one that demanded defensive discipline and clinical use of the rare moments they could hurt the visitors on the break. A low block without the finishing to punish opponents on the counter is simply a slow surrender.”
The data from the pipeline was exactly the same, but thanks to this tweak the output changed completely.
The second change: how I formatted the context
I implemented this one from a course I’m working through called Agentic AI Engineering from Towards AI.
The lesson was about Context Engineering, the discipline of deciding what goes into a model’s context window in order to make it follow the right instructions.
One of the practical recommendations was: prefer YAML over JSON when providing structured data as input.
I’d been using Python dicts serialized as JSON. The lesson argued YAML is more token-efficient and reads more naturally alongside prose examples in a prompt.
I ran a quick comparison on my own <tactical_labels> block.
JSON version:
{
"home_press_style": "pressed_aggressively_allowing_few_passes",
"home_defensive_shape": "compact_block",
"home_territorial_dominance": "dominated_final_third"
}
YAML version:
home_press_style: pressed_aggressively_allowing_few_passes
home_defensive_shape: compact_block
home_territorial_dominance: dominated_final_third
The YAML block is shorter (no brackets, no quotes, no commas), and it reads more like prose which matters when it’s sitting next to few-shot examples written in natural language. The model processes both from the same context window. Found out that small token savings compound across many calls, and a cleaner context means less noise for the model to work through.
The other Context Engineering principle I applied was prompt structure.
The lesson covered something called the “lost-in-the-middle” problem: LLMs tend to underweight information placed in the middle of long contexts, so what they remember best is what comes first and what comes last.
The practical implication: you have to put your most important instructions at the START (system prompt) and at the END (<instructions> block). Dynamic content like match labels and retrieved facts goes in the middle.
And for caching: put static content first. That way the system prompt and few-shot examples don’t change between calls. Both go at the top, before any dynamic match data. This allows the provider to cache the static prefix and skips re-processing it on every requests.
My prompt structure now looks like this:
<system_prompt> ← static, cached
[scouting style instructions]
<few_shot_examples> ← static, cached
[two reference match analyses]
<match_context> ← dynamic per call
[YAML labels for this match]
<instructions> ← static, repeated at end
[core constraints, re-anchored]
The model gets its instructions twice.
Once at the top before anything else and once at the bottom after seeing the data. This is how we can avoid lost-in-the-middle.
A broader principle connecting Wordalisation and Context Engineering
Both are fundamentally about the same thing: giving the model the right kind of information.
Wordalisation says: don’t give the model numbers and ask it to interpret them. Classify the numbers into domain language first, then give the model language it can work with.
Context Engineering: don’t give the model everything you have. Select what’s relevant, compress what’s not, format it so the model can use it without fighting its own architecture.
Since the LLM does not work as a calculator nor a database we need to feed it with the right data: language.
Key Takeaways
The RAG system has a well curated data pipeline but now, at the point where structured data meets the language model, there’s a much needed translation layer that needs to be included.
The data flows like: Numbers → Labels → LLM → football insight.
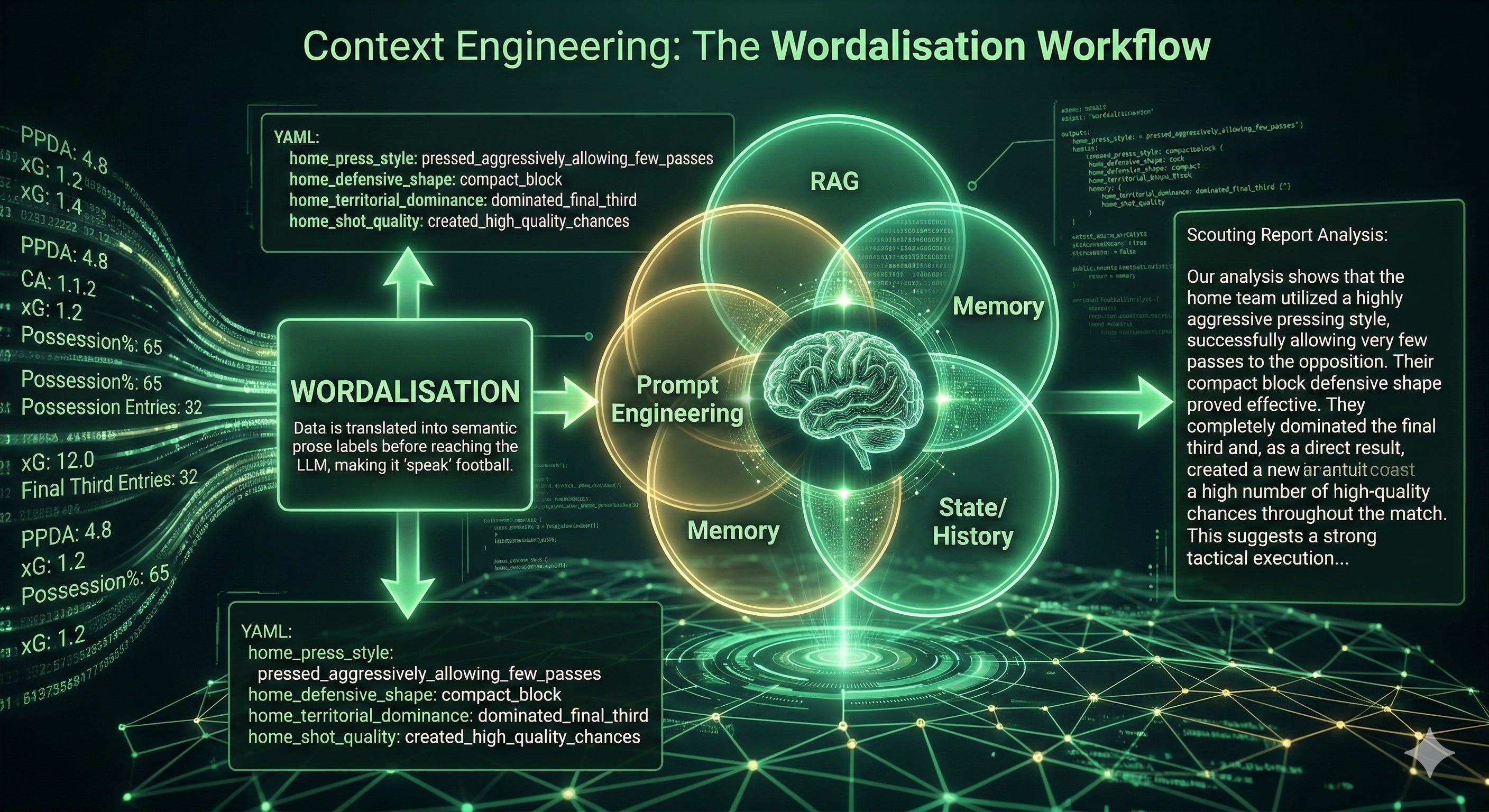
That’s exactly the principle of Wordalisation applied to Context Engineering.
Hope this gives you an idea on how to translate metrics into text, by leveraging LLM’s text generation capabilities.
Till next time,
Ricardo.